Testin Testing
Bionic-LXDE
-
Heute mal was ganz außergewöhnliches für mich, wir testen mal einen Desktop
")
rock64@rockpro64:~$ uname -a Linux rockpro64 4.4.132-1066-rockchip-ayufan-g48b9d1455011 #1 SMP Thu Jul 19 14:31:04 UTC 2018 aarch64 aarch64 aarch64 GNU/LinuxWas ist LXDE ?
LXDE ist eine schnellere und ressourcenschonende freie Desktop-Umgebung.
Quelle: https://wiki.lxde.org/de/Hauptseite
Bootvorgang
Seit der Version 0.7.7 sind wir da ja ein ganzes Stück nach vorne gekommen. Boot Vorgang so weit problemlos, bis auf das die NVMe Karte wohl nur gelegentlich eingebunden wird.
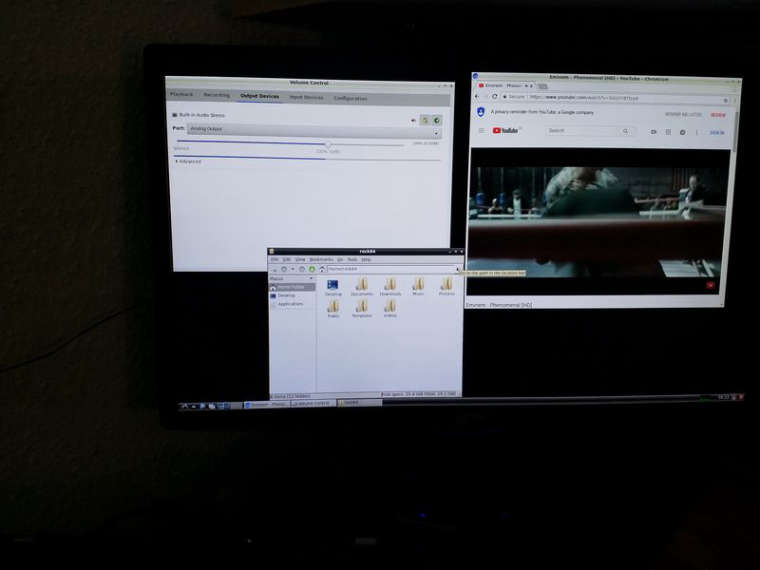
Desktop Login erscheint, einloggen und man ist auf dem Desktop. Direkt mal Chromium angeschmissen. Ok, die Videos laufen, aber man merkt die fehlende 3D-Unterstützung. Sie laufen, aber na ja....leichte Fehler sind sichtbar in den Video's.
Sound: Der Sound müsste standardmäßig über HDMI ausgegeben werden, hatte ich irgendwo im IRC mal mitbekommen. Doof wenn man keine Lautsprecher im Monitor hat und nicht weiß wie man das umschaltet!?? Ich würde es bevorzugen, wenn die Standard Einstellung "Line Out" wäre.
Fix HDMI -> Line Out
sudo apt-get install pavucontrolDas Programm öffnen, findet man unter "Sound & Videos". Dann unter "Configuration" das erste Device auf "Mutichannel Output" umstellen, die anderen vorher auf "OFF". Danach kam aus meinen Boxen was raus.
Ansonsten sieht der Desktop nutzbar aus. Reagiert zügig auf Mausbewegungen usw.
Download
Releases · ayufan-rock64/linux-build
Rock64 Linux build scripts, tools and instructions - Releases · ayufan-rock64/linux-build

GitHub (github.com)
Fazit
Kann ich nicht abgeben, weil ich auf den SOC's keinen Desktop nutze, ich nutze diese Platinen nur als Headless Server. Aber, wenn jemand daran Spaß hat - bitte. Man kann es nutzen auch wenn noch einige wichtige Dinge nicht unterstützt werden.
-
-
-
-
-
Mainline Kernel 4.20.x
Verschoben Images -
-
stretch-minimal-rockpro64
Verschoben Linux -
bionic-containers-rockpro64
Verschoben Linux